昨天雖然在介紹各個集合時,也順便提到了每個集合的專用函式。但其實在寫 elixir 時最常用到的,是兩個更為泛用的集合處理模組:Enum 及 Stream。而這兩個模組裡,包含了許多函數式編程共通的高階函式。例如最著名的三個高階函式,map/2、filter/2、reduce/3。
在之前提過 lambda 、匿名函式時,有講到函式是一級公民,可以當做其它函式呼叫的參數,也可以當做函式的回傳值。所以我們就把接收函式為參數的函式及回傳函式的函式,叫做高階函式。不過在一般的情況下,當你聽到高階函式時,大多數指的是接收函式為參數的函式這種。
2017 年的現在,連 Java 都有 lambda ,JavaScript 陣列也內建 map 跟 reduce 了,你一定也用過高階函式,只是也許你沒有意識到而己。不過我們還是來解釋一下高階函式有什麼好處。
例如我們有兩段程式如下 :
(以 JavaScript 為例,單純因為 iT 邦幫忙不幫 elixir 上色)
(Update: 我發現不要跟它說是 elixir 的話,iT 邦幫忙會把程式碼當做 ruby 來上色 XD)
/* JavaScript */
//1
console.log("Get some lobster")
putInPot("lobster")
putInPot("water")
//2
console.log("Get some chicken")
boomBoom('chicken')
boomBoom('coconut')
很多 programmer 會在這裡決定這段程式碼已經 ok,無法再改善了。因為它們呼叫了不同的函式,參數也大不相同。但有些人能發現這兩段程式,在另一個層次上有很像的地方:流程的形狀。這兩段都是先呼叫 console.log,而且跟第一個函式呼叫的參數有關,緊接著有兩個相同的函式呼叫。但呼叫的函式不同就是那些人停住的原因。而高階函式的概念,讓我們知道這段程式可以再進一步抽象成這樣:
/* JavaScript */
function cook(meat, soup, f) {
console.log("Get some " + meat)
f(meat)
f(soup)
}
//1
cook("lobster", "water", putInPot)
//2
cook("chicken", "coconut", boomBoom)
再用上匿名函式,我們甚至可以不需要預先定義好的 putInPot 及 boomBoom。
/* JavaScript */
cook("lobster", "water", x => console.log("pot " + x))
cook("chicken", "coconut", x => console.log("boom " + x))
類似 OO 的 design pattern,在函數式編程中,有許多泛用的集合操作方式 (很多都是從數學理論那邊直接拿過來用的)。最重要的三個,就是 map/2, filter/2 及 reduce/3。
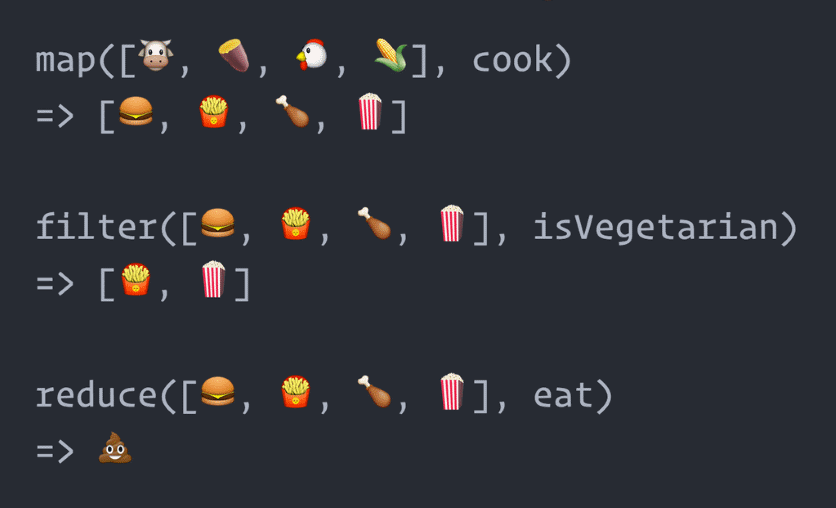
reduce/3reduce 在其它的函數式編程語言裡有時叫做 fold 或是 foldl。它會將一個集合及一個起始值,用傳入的函式折疊成最終的結果。該最終結果的型別會與起始值相同。我們再一次試試著實作串列加總,改用 Enum.reduce/3:
Enum.reduce([1, 2, 3, 4, 5], 0, fn (i, total) ->
total + i
end)
#=> 15
你傳進去的函式 (不一定要匿名) 需要處理兩個參數,第一個是集合中目前的元素 (在我們的例子裡是 i),第二個是上一步回傳的結果 (在例子中就是 total)。如果是第一個元素時,會把起始值,也就是 0 當做 total 傳進去。
如果你用的是 fold 或 foldl,幾乎都規定要傳起始值。但若叫 reduce 時,如果不傳起始值,就會拿集合的第一個元素當起始值,然後從第二個元素開始遍歷。
之所以從 reduce/3 開始介紹,是由於其它的高階函式,包括 map/2 及 filter/2,大多都可以用 reduce/3 實作出來。幾乎可以說是高階函式的 prima materia。(哈哈終於讓我用到鍊金術哏了)
map/2map 會將一個集合轉換成另一個長度相同的集合。新集合的元素的型別,就是傳入函式的回傳型別。
Enum.map([1, 2, 3, 4, 5], fn i ->
"C#{i * 3}"
end)
#=>["C3", "C6", "C9", "C12", "C15"]
map2 = fn (collection, f) ->
Enum.reduce(collection, [], fn (i, total) ->
total ++ [f.(i)]
end)
end
filter/2filter 要傳入的函式必須回傳布林值,若該元素應用到函式上回傳 true 時,這個元素才會被留下來,否則就會過濾掉。所以這個函式會回傳長度等於或小於原集合,且元素型別與原集合元素型別相同的新集合。
Enum.filter([1, 2, 3, 4, 5], fn i ->
i % 2 == 0
end)
#=> [1, 3, 5]
filter2 = fn (collection, f) ->
Enum.reduce(collection, [], fn (i, total) ->
if f.(i), do: total ++ [i], else: total
end)
end
順帶一提,Enum.reject/2 是這個函式的相反版本。拒絕掉讓函式回傳 true 的元素。
之前唸 Dave Thomas 的 Programming Elixir 時,有一句話給了我很大的啟發,他說:
Functional programming is like a journey of data transforming
函數式編程,就像是一趟資料轉換的旅程
我們來編造一個範例,假設我們有這樣的資料:
students = [
%{name: "John Doe", age: 18},
%{name: "Mary Su", age: 21},
%{name: "Chris Smith", age: 16},
%{name: "Bob Doe", age: 20},
]
我們想要拿到所有 18 歲以上的人,不重覆的姓。若在 OO 語言裡用 for 來處理,會長得像是這樣:
/* JavaScript */
let result = [] //宣告一個額外的結果陣列
for(let s of students) { //遍歷
if (s.age >= 18) { //判別年齡
let [first_name, last_name] = s.name.split() //切開姓名
if(result.indexOf(last_name) == -1) { //判別重覆
result.push(last_name) //把需要的值放進結果陣列裡
}
}
}
result
如果我們剛剛的條件要減少、增加或修改,整個結構會愈來愈複雜,以至於愈來愈難維護調整。也很難讓這段程式放到其它地方使用。
我們試著用資料轉換的旅程的想法來試試:
students
|> Enum.filter(&(&1.age >= 18)) # 判別年齡
|> Enum.map(fn %{name: name} -> String.split(name, " ") end) # 切開姓名
|> Enum.map(fn [_, last_name] -> last_name end) # 只拿姓
|> Enum.uniq # 去掉重覆
行數少了一半,讀起來反而更清楚。而且之後要新增條件,只要找到適當的地方 pipe 進新的函式就可以了。值得注意的是,我故意把切開姓名跟取姓分成兩步處理。如果你讀過歐萊禮的「深入淺出設計模式)」(順帶一提,這是本好書),第一章就告訴你用合成代替繼承,因為繼承三不五時會帶著一堆副作用來踩你的腳。
而在函數式編程裡,我們不太相信 reuse 這件事,而是專注在做出一堆很短,處理一件小事的簡單函式,再透過 function composition,依需求組合這些通用的小函式,把資料從原始的結構,一步步逐漸轉成我們想要的最終結果。這樣程式會更彈性,也更少錯誤。
Programming Elixir 裡有這麼一張圖,可以讓你更理解這個概念: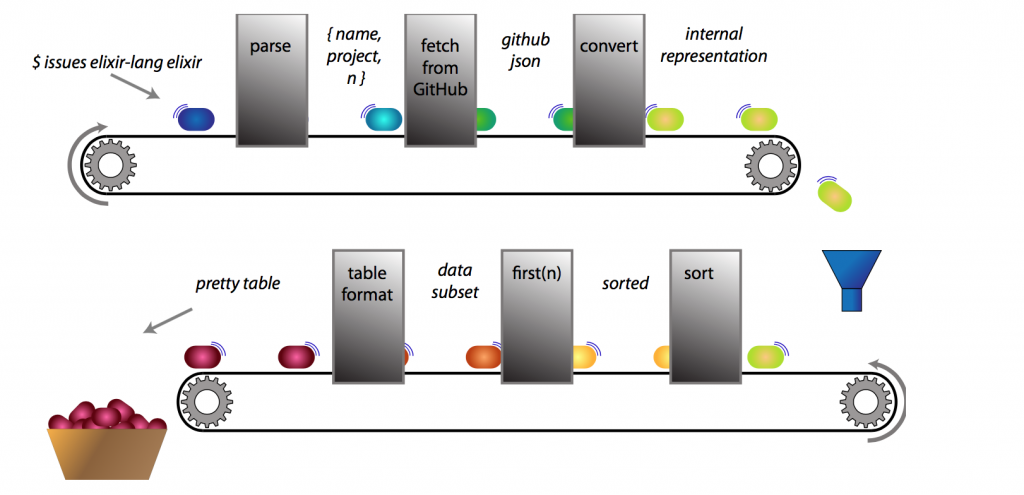
Enum 函式例如 Enum.all?/2、 Enum.any?/2、 chunk 系列、map 系列,還有 Enum.scan/3 及 Enum.zip/3 等等。總之如果你想用特別的方式對集合進行操作,第一步一定是先來看 Enum 模組是不是有符合你需求的函式。
如果你之後去使用 Ramda 或是 lodash/fp ,還有 Rx.js ,甚至改學 Haskell,在過程中,你會不斷的發現這些函式庫及語言裡面的函式,概念上幾乎都是重疊的,有時只是名稱不同。你就會開始體會,這些全部都來自於他們背後的那套數學的形式系統。
然後也許你就會理解這句話:
學了 LISP 之後,有可能你這輩子再也不會寫 LISP。但是之後不管用什麼語言,你所寫出來的程式都跟 LISP 沒什麼兩樣。
Enum 是泛用於各種集合的模組map、filter、reduce,還有其它明天接續這個主題,來聊聊 Stream 這個模組。
Happy hacking! 明天見。




 iThome鐵人賽
iThome鐵人賽